
Apache Spark is one of the most powerful open-source engines for big data processing. It is designed to be fast, easy to use, and highly scalable. But before diving into coding with Spark, it’s crucial to understand how it works under the hood.
What is Apache Spark?
Apache Spark is a distributed computing engine used for large-scale data processing. It can process data in batches and real-time streams, and works well with big data technologies like Hadoop, HDFS, and various cloud platforms.
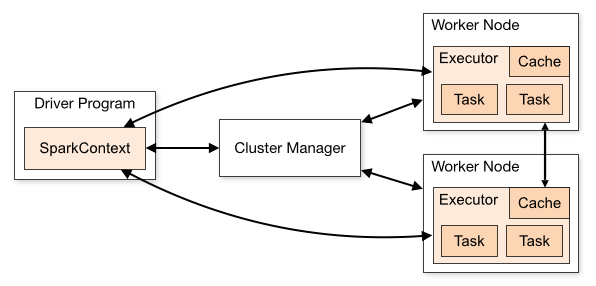
Key Components of Spark Architecture
Spark follows a master-slave architecture with the following main components:
1. Driver Program
The Driver is the brain of a Spark application.
It contains your main() function and runs on a master node.
It’s responsible for:
Converting code into tasks
Scheduling those tasks on different worker nodes
Handling job execution, task failures, and more
Think of it as the project manager who knows the plan and tells everyone else what to do.
2. Cluster Manager
Spark needs a Cluster Manager to handle resource allocation (CPU, memory) across machines.
Types of cluster managers Spark can work with:
Standalone – comes built-in with Spark
Apache Hadoop YARN
Apache Mesos
Kubernetes
The cluster manager decides which machines to use and how much resource to assign to each application.
3. Executors
Executors are worker processes launched on the worker nodes.
Each executor is responsible for:
Running part of your code (tasks)
Storing data in memory or disk during computation (caching)
Communicating with the Driver
Each Spark application has its own set of executors — they die when the application ends.
4. Worker Nodes
These are the machines in the cluster where executors run.
Worker nodes perform the actual computation and store intermediate results.
They report back progress and status to the driver.
How Spark Application Runs (Step-by-Step)
Let’s walk through how Spark works when you submit an application:
Submit the Application
You run a Spark program using spark-submit.
The driver starts and connects to the cluster manager.
Resource Allocation
The cluster manager allocates resources (executors) on worker nodes.
Executor Launch
Executors are launched on those worker nodes.
Task Distribution
The driver divides your job into smaller stages, which are further broken into tasks.
Tasks are sent to executors.
Execution
Executors run tasks, process data, and store results.
Result Collection
Results are collected by the driver or written to storage (HDFS, S3, DBs, etc.).
Shutdown
After job completion, executors shut down.
Cluster Mode vs Client Mode
When using Spark on YARN or Kubernetes, you can choose between two deployment modes:
Mode | Driver Location | Use Case Example |
|---|---|---|
Client | Runs on local machine | Good for development and testing |
Cluster | Runs on cluster | Best for production workloads |
In Client mode, the driver runs on your local machine.
In Cluster mode, the driver runs on a worker inside the cluster.
Visualization: Spark Architecture Diagram
+-------------------+ +------------------------+
| Your Spark App | | Cluster Manager |
| (Driver) |<--------->| (YARN / K8s / Standalone) |
+-------------------+ +------------------------+
|
| Launch Executors
v
+---------------------+
| Worker Node 1 | --> Executor 1 (Runs Tasks)
+---------------------+
| Worker Node 2 | --> Executor 2 (Runs Tasks)
+---------------------+
Summary of Responsibilities
Component | Role |
|---|---|
Driver | Plans and coordinates job execution |
Executors | Run code and store intermediate results |
Cluster Manager | Allocates resources and launches executors |
Worker Nodes | Machines where executors live |
Final Thoughts
Understanding Spark’s architecture is essential for building scalable data pipelines. It helps you write efficient code, tune performance, and debug failures better.
Whenever you’re building a Spark job, remember:
The Driver is the brain
Executors are the workers
The Cluster Manager is the manager of resources